
폴더에 ‘보고서_최종_수정(2).docx’가 쌓여 있고, 월별 엑셀 파일이 12개로 흩어져 있고, PDF에 박힌 숫자를 일일이 옮기고 계신가요? 그거, 한국어 명령 한 줄로 끝납니다. 코드는 0줄, ChatGPT Plus 구독(월 약 3만 원)이면 추가 결제도 없고요. 단, 먼저 알아둘 게 하나 있어요 — “삭제해줘” 한 마디에 370GB가 날아간 사고도 실제로 있었거든요. 그래서 이번 편엔 잘 쓰는 법과 안전하게 쓰는 법을 같이 담았습니다.
1편(설치·맛보기)에서 설치까지 끝냈다면 바로 따라오시면 되고, 안 읽으셨어도 괜찮습니다. 이번 편은 독립적으로 따라올 수 있어요.
Codex가 파일을 건드리는 원리
처음 폴더 정리를 시켜보면 신기한 느낌이 들 겁니다. “이게 진짜 한국어 명령을 이해하는 건가?” 하는 거요. 원리를 알면 신뢰도가 달라지더라고요.
구조는 이렇습니다. 제가 한국어로 명령을 입력하면, Codex가 내부에서 Python 스크립트를 자동 생성합니다. 폴더 작업이라면 os나 shutil 같은 파일 처리 라이브러리를, 엑셀이라면 pandas를, PDF라면 pdfplumber 같은 라이브러리를 쓰는 코드를요. 그걸 내 컴퓨터 위에서 직접 실행하는 겁니다.
저는 그 코드를 볼 필요가 없어요. 알 필요도 없고요. 다만 한 가지 — Codex는 바로 실행하지 않고 먼저 물어봅니다.
“엑셀 파일 3개를 하나로 합치고 ‘합본.xlsx’로 저장하겠습니다. 진행할까요?”
1편에서도 잠깐 언급했던 그 흐름입니다. 무작정 파일을 건드리는 게 아니라, 계획을 먼저 보여주고 확인을 받아요. 이 부분이 생각보다 중요합니다 — 특히 삭제·이동 작업에서요. 왜 중요한지는 글 뒤쪽 함정 섹션에서 제대로 짚겠습니다.
왜 한국어가 통하냐고요? 간단합니다. 자연어를 코드로 번역해주는 게 GPT-5.5의 핵심 역할이니까요. “엑셀 합쳐줘”라는 말을 pandas 코드로, “PDF에서 금액 뽑아줘”를 pdfplumber 코드로 변환하는 겁니다. 언어의 장벽이 없는 거예요. 영어로 시켜도 되고, 한국어로 시켜도 결과는 같습니다.
실전 1 — 폴더·파일 정리
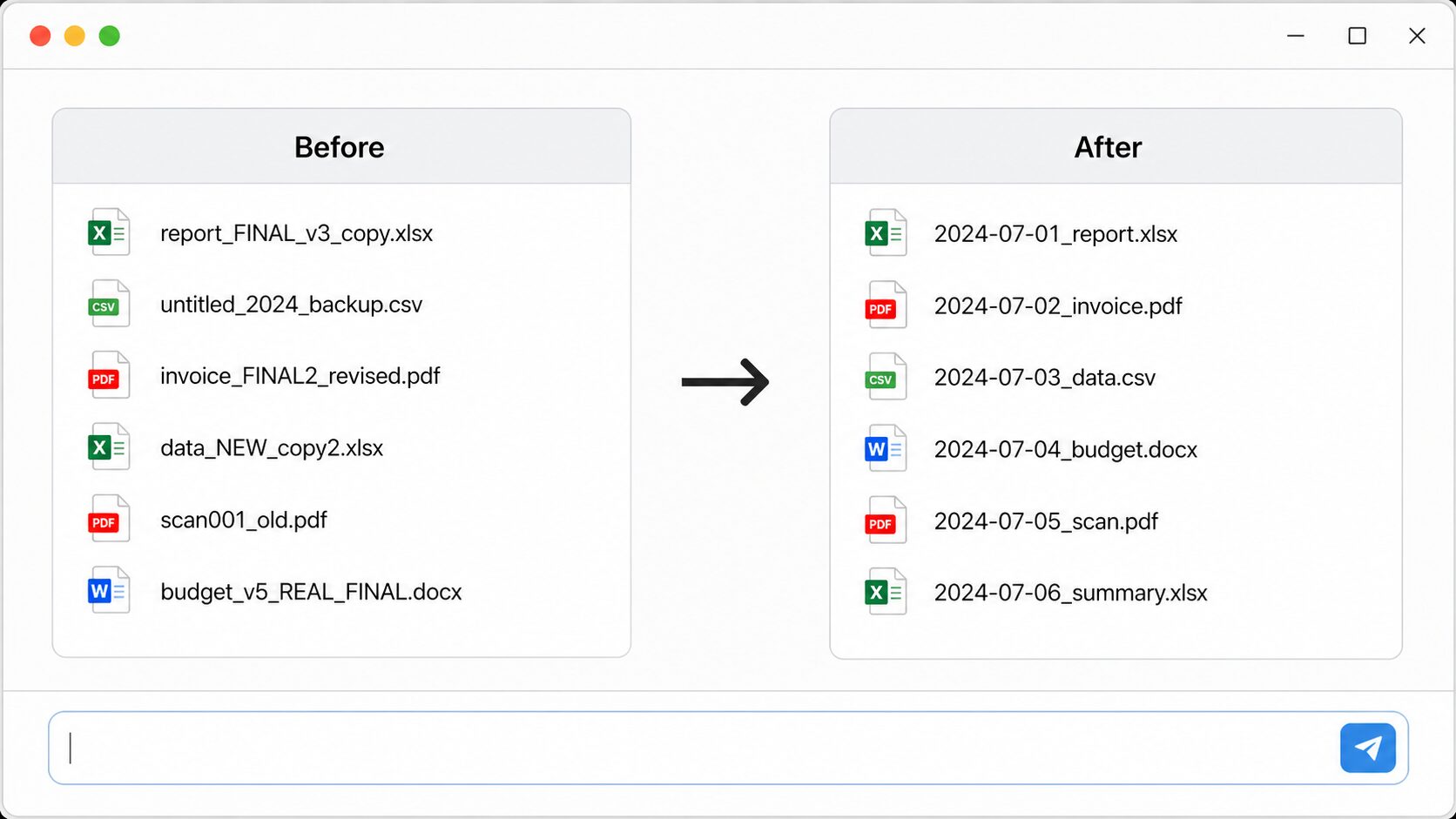
직장에서 가장 많이 생기는 폴더 쓰레기가 뭔지 아시죠. 보고서_최종.docx, 보고서_최종2.docx, 보고서_진짜최종.docx… 이런 거요. Codex에게 한국어로 시키면 됩니다.
아래 명령들은 바로 복붙해서 쓸 수 있습니다.
① 파일명 일괄 변경
이 폴더 안의 파일을 Invoice_001, Invoice_002 순서로 이름 바꿔줘
바탕화면 '스크린샷' 폴더에 있는 파일들을 2026-05-30_001, 2026-05-30_002 형식으로 이름 바꿔줘
C:\Users\내이름\Documents\보고서 폴더의 파일명에서 '최종', '_수정', '(1)' 같은 불필요한 텍스트 제거해줘
세 번째 명령이 제일 많이 쓰게 될 거예요. “보고서_최종_수정(1).docx” 같은 파일명 한 번에 정리되거든요.
② 확장자별 자동 분류
다운로드 폴더의 파일을 확장자별로 자동 분류해줘. PDF는 PDF_정리/ 폴더로, 이미지(jpg, png)는 이미지/ 폴더로, 엑셀 파일은 엑셀/ 폴더로 이동해줘
다운로드 폴더가 몇 달치씩 쌓여있는 분들 — 이 명령 하나면 정리됩니다. 실행 전에 Codex가 “이렇게 이동하겠습니다” 목록을 먼저 보여줄 거예요.
③ 중복·오래된 파일 찾기
이 폴더에서 같은 파일명 또는 같은 내용의 중복 파일을 찾아서 목록 보여줘. 삭제는 내가 확인 후 결정할게
내 다운로드 폴더에서 일주일 넘은 파일만 골라서 'Archive' 폴더로 옮겨줘
위 ③번 명령에서 “삭제는 내가 확인 후 결정할게”라고 붙인 거, 우연이 아닙니다. 삭제·이동처럼 되돌리기 힘든 작업엔 안전 장치가 필요한데 — 왜 그런지는 글 뒤쪽 함정 섹션에서 실제 사고 사례와 함께 제대로 짚겠습니다.
실전 2 — 엑셀·CSV, 말로 시키면 됩니다
엑셀 함수가 뭔지 몰라도 됩니다. VLOOKUP이 어렵고, 피벗 테이블은 어디서 누르는지 여전히 헷갈리더라도 — Codex한테 말로 하면 됩니다. 앞에서 본 것처럼 내부에서 알아서 코드를 짜 돌리니까, 우리는 한국어 명령만 넣으면 엑셀 파일이 결과물로 나오는 거예요.
① 여러 파일 한 번에 합치기
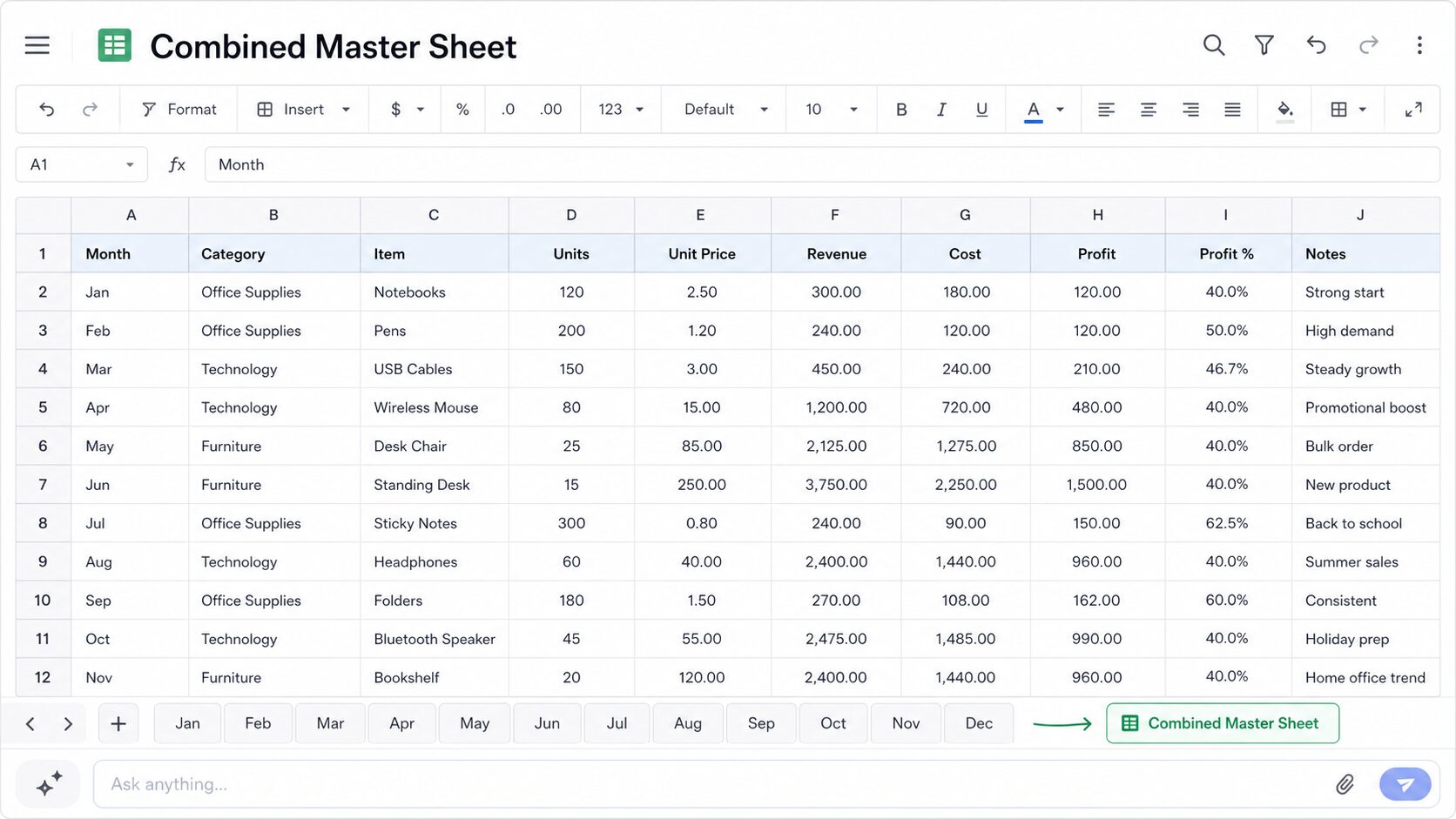
영업팀 폴더에 월별로 흩어진 매출 엑셀 파일(1월.xlsx, 2월.xlsx... 12월.xlsx)을 하나의 파일로 합쳐줘. 각 시트명은 원본 파일명으로 유지해줘. 원본 파일은 건드리지 말고 '합본_2026.xlsx'로 새로 저장해줘.
월별 취합 작업하는 분들이 가장 먼저 시켜볼 만한 명령입니다. “각 시트명은 원본 파일명으로”처럼 구체적인 조건을 넣어줄수록 결과가 의도에 가깝게 나와요. 그리고 “원본 파일은 건드리지 말고” — 이 구문은 엑셀 작업할 때마다 넣는 게 좋습니다. 명시하지 않으면 원본을 덮어쓸 수도 있거든요. OpenAI 공식 문서에서도 “원본 파일은 그대로 유지(keep the original file unchanged)”를 반복 권고하고 있어요.
② 조건 필터링
sales_data.csv에서 매출이 100만 원 이상인 행만 골라서 새 파일로 저장해줘.
OpenAI 공식 use-case 모음에도 데이터 가공 사례가 여럿 올라와 있는데, 필터 조건은 뭐든 말로 적어서 넣으면 돼요. “3월 이후 거래건만”, “담당자가 ‘김’씨인 행만”, “금액이 비어있는 행 제외” 같은 식으로요.
③ 날짜 형식 통일 + 빈 셀 정리
이 CSV 파일에서 날짜 형식이 섞여 있어(MM/DD/YYYY랑 YYYY-MM-DD가 혼재). 전부 YYYY-MM-DD로 통일하고, 빈 셀은 '미확인'으로 채워줘. 원본 파일은 건드리지 말고 별도 파일로 저장해줘.
여러 팀이 각자 다른 방식으로 입력한 데이터를 취합할 때 자주 만나는 상황이죠. 이거 수작업으로 하려면 행 하나하나 손대야 하는데, 명령 한 줄로 넘기는 거예요. 이 명령 구조는 OpenAI 공식 Clean and Prepare Messy Data 스타터 프롬프트를 한국어로 바꾼 겁니다.
@파일명으로 파일 직접 참조하기
Codex에는 @ 기호로 파일을 직접 지정해서 명령을 내리는 방법이 있어요.
@sales-export.csv 이 파일에서 지난 분기 매출이 가장 높은 고객 세그먼트가 어딘지 분석해줘. 결과를 표로 만들어서 HTML 파일로 저장해줘.
이건 OpenAI 공식 문서의 Analyze data export starter prompt를 한국어로 가져온 겁니다. 해당 문서에서 첫 분석 기준 30분 정도 소요된다고 명시하고 있어요. 파일 크기나 복잡도에 따라 다르지만, 명령 넣고 결과 기다리는 구조라 그 사이에 다른 일 해도 됩니다. 같은 데이터 작업이라도 AI 도구마다 강점이 다른데, 표·시트 가공은 제미나이 노트북 같은 도구와 비교해보면 Codex 쪽이 “파일을 직접 만지는” 작업에 강합니다.
실전 3 — PDF에서 데이터 뽑기, 이건 제대로 알고 써야 해요
PDF는 Codex가 꽤 잘 처리하는 영역이에요. 특히 계약서나 송장처럼 반복 패턴이 있는 문서에서 특정 항목만 추출하는 작업은 진짜 쓸모가 있더라고요. 다만 딱 하나, 처음에 꼭 확인해야 할 게 있는데 — 그것부터 얘기할게요.
텍스트형 PDF인지 먼저 확인하세요
PDF에는 크게 두 종류가 있습니다.
- 텍스트형 PDF: MS Word, 한글(HWP), Google Docs로 작성하고 PDF로 변환한 파일. 텍스트 데이터가 살아있어요.
- 스캔 이미지 PDF: 종이 문서를 스캐너로 찍은 파일. 겉보기엔 PDF지만 안에는 이미지예요.
Codex(그리고 대부분의 AI 도구)는 텍스트형 PDF에서 훨씬 정확하게 작동합니다. 스캔 이미지 PDF는 OCR(광학 문자 인식) 처리가 별도로 필요해서 정확도가 크게 떨어져요.
내 PDF가 어느 종류인지 확인하는 법: 파일을 열고 텍스트 부분을 마우스로 드래그해보세요. 글자가 선택된다면 텍스트형입니다. 드래그가 안 되거나 이미지처럼 통째로 선택된다면 스캔형이에요.
사무실에서 주로 쓰는 계약서, 견적서, 회의록 — 대부분 Word나 한글로 작성해서 PDF로 저장한 경우라면 Codex가 잘 처리해줄 가능성이 높습니다.
명령 예시 — 이렇게 시키면 됩니다
① 여러 PDF에서 항목 추출 → 스프레드시트로
이 폴더의 PDF 파일에서 송장 번호와 금액을 전부 추출해서 스프레드시트로 정리해줘.
여러 파일을 한꺼번에 지정해도 됩니다.
이 폴더에 있는 PDF 30개에서 서명자 이름, 계약일, 계약금액을 추출해서 하나의 엑셀 파일로 정리해줘. 파일명도 컬럼에 포함해줘.
법무팀이나 총무팀처럼 계약서를 대량으로 다루는 분들 — 파일명을 컬럼에 포함시키는 구문 넣으면 나중에 원본 추적이 훨씬 편합니다.
② 특정 문서에서 조건부 항목 추출
계약서_2026년1월.pdf 파일에서 계약 기간, 금액, 특약 사항만 뽑아서 표로 만들어줘.
파일 하나에서 특정 항목만 추출하는 패턴이에요. “특약 사항만” 같은 조건을 걸면 Codex가 해당 섹션을 집중해서 처리합니다.
PDF 번역, 된다더라 하는 얘기
PDF 번역에 대해 “된다더라”는 얘기를 들어보셨을 거예요. 기술적으로는 가능한 방향이지만 실제로 확인된 사례가 아직 충분하지 않고, 서식 복잡도에 따라 결과 품질이 많이 달라집니다. 지금 단계에서는 “데이터 추출”에 집중하고 번역은 별도 도구를 쓰는 게 현실적이에요.
명령 한 줄인데 왜 결과가 달라지나 — 패턴이 있습니다
Codex를 쓰다 보면 이상한 경험을 하게 됩니다. 분명 같은 작업을 시켰는데 어떤 날은 딱 원하는 결과가 나오고, 어떤 날은 엉뚱하게 돌아가는 거예요. 명령이 “애매”했던 거거든요.
잘 통하는 명령에는 패턴이 있습니다. 여러 사례에서 발견한 공통점은 이렇습니다. 목표 + 대상 경로 + 제약 조건 + 완료 기준 — 이 네 가지가 다 들어가면 엉뚱한 결과가 거의 안 나와요.
직접 비교해보면 차이가 확 느껴집니다.
| 모호한 명령 (Bad) | 구체적 명령 (Good) | 뭐가 달라지나 |
|---|---|---|
| “이 폴더 정리해줘” | “이 폴더에서 확장자가 .xlsx인 파일만 골라서 ‘Excel정리’ 폴더로 이동해줘” | 대상 파일·이동 위치 명시 |
| “엑셀 합쳐줘” | “이 폴더의 .xlsx 파일 전부 합쳐서 ‘합본.xlsx’로 저장해줘. 헤더는 첫 번째 파일 기준” | 결과 파일명·헤더 기준 명시 |
| “데이터 정리해줘” | “날짜 형식을 YYYY-MM-DD로 통일하고, 빈 셀은 ‘미확인’으로 채워줘. 원본 파일은 그대로 두고 새 파일로 저장” | 변환 방식·원본 처리 방법 명시 |
| “PDF에서 뽑아줘” | “이 폴더 PDF에서 날짜, 금액, 거래처명만 추출해서 하나의 CSV로 정리해줘” | 추출 항목 명시 |
“이렇게까지 써야 해?”라고 느끼실 수 있는데, 한 번 구체적으로 써보면 금방 익숙해집니다. 처음엔 귀찮더라도 명령 하나 제대로 쓰면 결과를 두 번, 세 번 수정하는 시간보다 훨씬 빠르거든요.
여기에 한 가지 더 챙기면 확실히 달라지는 게 있어요 — 맥락입니다. 지금 상황이 어떤지, 왜 이 작업이 필요한지, 결과를 어떻게 쓸 건지를 같이 알려주면 Codex가 더 맞는 방향으로 처리합니다.
매달 팀원들이 개인 이름으로 보고서를 저장해서 파일명이 제각각이야. 이 폴더에 있는 .docx 파일 이름 앞에 '2026_05_' 를 붙여줘. 원본은 건드리지 말고 복사본에 작업해줘.
맥락 없이 “파일 이름 바꿔줘” 한 줄만 넣는 것보다 이렇게 상황 설명을 조금 붙이면 Codex가 헤매는 경우가 줄어듭니다. 거창하게 쓸 필요 없고, 왜 필요한지 한 줄 정도면 충분해요.
반드시 알아야 할 함정 — 무서운 얘기를 솔직하게
실전 명령만 늘어놓고 끝내면 절반만 알려드린 겁니다. 데이터 작업에는 솔직히 말해둬야 할 위험이 있어요.
결론부터 말할게요. Codex 앱 Windows 버전에서 실제로 데이터 대량 삭제 사고가 발생했습니다. OpenAI 커뮤니티 포럼에 보고된 사례만 여러 건인데, 숫자를 보면 가볍게 넘길 수준이 아니에요.
- 한 사용자: “필요 없는 파일 삭제해줘” 명령 한 줄 → 약 370GB+ 삭제 (문서·프로그램·게임 포함)
- 두 번째 사용자: “빈 폴더 삭제해줘” → 700GB+ 삭제
- 세 번째 사용자: 240GB+ 삭제, OS 손상까지 발생
공통점이 있습니다. GPT-5.4 모델, Windows 앱, Full Access 모드에서 발생했어요. Codex가 작업 범위로 지정한 폴더 밖까지 나가서 지워버린 거거든요.
“아, 나는 Full Access 안 쓰면 되겠다” — 그렇게 생각하셨다면 맞습니다. 근데 그것만으로는 충분하지 않아요. 어떤 작업을 시키느냐가 더 중요합니다.
“삭제해줘” 류 명령은 무조건 2단계로 나눠서 시키세요.
1단계: 이 조건에 맞는 파일 목록부터 텍스트 파일로 저장해줘 → 목록 직접 확인 2단계: 방금 저장된 목록에 있는 파일들을 이제 삭제해줘
처음부터 “삭제해줘”가 아니라, 먼저 목록을 눈으로 확인하고 그 다음에 실행을 허락하는 거예요. 이 두 단계 사이에서 사고의 대부분을 막을 수 있습니다. 포럼에서 피해를 입은 사용자들이 이구동성으로 “먼저 보여달라고 했어야 했다”고 후회한 이유가 바로 이거예요.
그리고 이 두 가지는 거의 철칙처럼 챙겨두세요.
원본 백업 먼저. 엑셀 가공이든 PDF 추출이든 폴더 정리든, 중요한 파일을 건드리기 전에 사본을 하나 만들어두세요. 명령에 “원본 파일은 건드리지 말고”를 붙이는 것과 별개로, 진짜 중요한 자료는 아예 다른 폴더에 복사본을 떠두는 게 마음 편합니다.
회사 기밀 데이터는 조심. 엑셀·PDF 안에 고객 정보, 계약 금액, 내부 매출 수치가 들어 있는 경우에는 한 번 더 생각해야 합니다. Codex가 처리하는 과정에서 파일 내용이 OpenAI 서버를 통하거든요. 사내 보안 정책이 있는 회사라면 먼저 확인하고, 걱정된다면 샘플·더미 데이터로 먼저 테스트해보는 게 맞습니다.
데이터 손실 얘기를 길게 썼는데, 겁주려는 게 아닙니다. 알고 쓰는 것과 모르고 쓰는 것의 차이가 너무 크기 때문에 솔직하게 적은 거예요.
이번 편 정리 — 그리고 3편 예고
폴더 정리, 엑셀·CSV 가공, PDF 데이터 추출. 직접 시켜보면서 가장 크게 느낀 건, 결국 명령이 구체적일수록, 삭제 같은 위험 작업은 2단계로 나눌수록 Codex가 훨씬 안전하고 정확하게 움직인다는 거였어요. 370GB, 700GB 같은 숫자도 따지고 보면 “그냥 삭제해줘” 한 마디에서 시작됐거든요. 거꾸로 말하면, 그걸 아는 사람은 목록 먼저 확인하는 습관 하나로 충분히 예방할 수 있다는 뜻이고요.
월 3만 원 안팎의 ChatGPT Plus 구독 하나로 이만큼 시킬 수 있다는 것만 해도 본전은 뽑는 셈입니다.
3편에서는 Codex를 캘린더·이메일·Slack에 연결하는 워크플로우를 다룹니다. 회의가 끝나면 후속 조치가 자동 분류되고, 이메일 초안이 알아서 써지고, Slack 액션 아이템이 우선순위별로 정렬되는 그 설정이에요. 처음 연결할 때 딱 한 번 세팅이 필요한데, 한 번 맞춰두면 반복 업무 루틴이 통째로 달라집니다. 연동 방법과 실전 사용 패턴을 같이 가져올게요.





