
ChatGPT Plus 결제 누르기 전에 잠깐만요
매달 ChatGPT Plus 월 3만 원 안팎, Claude Pro 월 3만 원 안팎 결제하시나요? 그 결제, 일단 멈추세요. 이번 달에 새로 나온 GPT-5.5도, Claude Opus 4.7 Thinking도, 신규 Gemini도 결제 한 푼 없이 지금 바로 던져볼 수 있는 사이트가 있습니다.
심지어 한 장에 몇백 원씩 들어가는 유료 이미지 AI(GPT 이미지 2.0·Imagen·Midjourney), 월 1만 원짜리 음악 AI(Suno·Udio)까지 여기서는 무료입니다. 이미 전 세계 500만 명이 매달 쓰는데, 한국에서는 의외로 덜 알려진 사이트, LM아레나입니다. 공식 주소는 arena.ai입니다. 한국어 인터페이스는 없지만, 메뉴 영어 5개만 알면 30초 안에 첫 배틀을 던질 수 있습니다.
저는 대학에서 생성형 AI 강의를 하면서 학생들에게 계속 묻는 질문이 있습니다. “어떤 AI를 추천하냐?” 처음에는 이 질문에 “Claude가 좋다” 또는 “GPT-5.5를 써봐라”고 답했는데, 한 두어 달 강의하다 보니 이게 잘못된 접근이라는 걸 깨달았습니다. 강의용으로 AI를 추천할 때 가장 정확한 방법은 학생들이 직접 여러 AI를 비교하고 던져 보게 하는 것이었거든요. 한 달 구독료 4만 원을 아낀 학생도, 반대로 진짜 살 만한 AI를 확신하고 결제하게 된 학생도 봤습니다. 하지만 매번 “ChatGPT 켜고, Claude 켜고, Gemini 켜고…” 하며 각각 가입하고 결제하게 할 수는 없었습니다. 그러다 발견한 게 바로 LM아레나입니다.
LM아레나의 정체: 블라인드 비교 시스템
LM아레나는 한국말로 치면 “AI들끼리 블라인드로 싸우는 사이트”입니다. 정확히 설명하면 이렇습니다.
- 블라인드 비교: 당신이 질문을 입력하면, 두 개의 AI가 답변합니다. 하지만 어느 AI가 어느 답변을 했는지는 안 보입니다.
- 사용자 투표: 두 답변을 읽고 “어느 게 더 나은 답변인가?”를 판단해 투표합니다. 1:1 대결처럼요.
- ELO 랭킹: 축구나 체스처럼 승리 수에 따라 각 AI의 순위가 매겨집니다. 더 좋은 경쟁사와 싸워서 이기면 점수가 더 올라갑니다.
2023년 UC Berkeley의 LMSYS 실험실에서 만들어진 이 사이트는, 2026년 1월에 독립 회사로 분리되어 아레나(Arena) 로 이름을 바꿨습니다. 언어모델(LM)만 평가하던 시대에서, 이미지 생성·코딩·검색 같은 여러 분야로 확장했다는 의미죠. 가입이나 로그인 없이 공식 웹사이트에 접속해 큰 텍스트 박스에 질문을 치고 엔터만 누르면 됩니다. 제 강의 현장에서 프로젝터에 바로 띄워 학생들 앞에서 실시간 실험할 수 있게 됐습니다. 추상적인 설명 대신 화면에서 직접 보는 비교라서 학생들 반응이 확 달라졌거든요.
빠르게 성장한 AI 랭킹 플랫폼
숫자로 보면 LM아레나의 영향력을 더 잘 알 수 있습니다.
2026년 1월 시점에 월간 활성 사용자가 500만 명입니다. 누적 투표 수는 5,000만 건 이상, 비교 대상 AI 모델은 350개 이상입니다. OpenAI ChatGPT부터 Google Gemini, Anthropic Claude, xAI Grok, 그리고 국내 모델들까지 거의 모든 주요 AI가 아레나에서 평가됩니다.
처음엔 UC Berkeley·Stanford·UCSD·CMU 같은 대학들이 함께 만든 학술 프로젝트였습니다. 2025년 5월 Seed $100M, 2026년 1월 Series A $150M을 유치하며 기업 가치 $1.7B(17억 달러) 의 유니콘 반열에 올랐습니다. Wei-Lin Chiang(CTO), Anastasios Angelopoulos(CEO)가 이끄는 독립 회사로 변신한 거죠. “LMArena”에서 “Arena”로 이름을 단순화한 것도 이 시점입니다.
영어 사이트지만 5단계면 끝 — 첫 배틀 시작하기
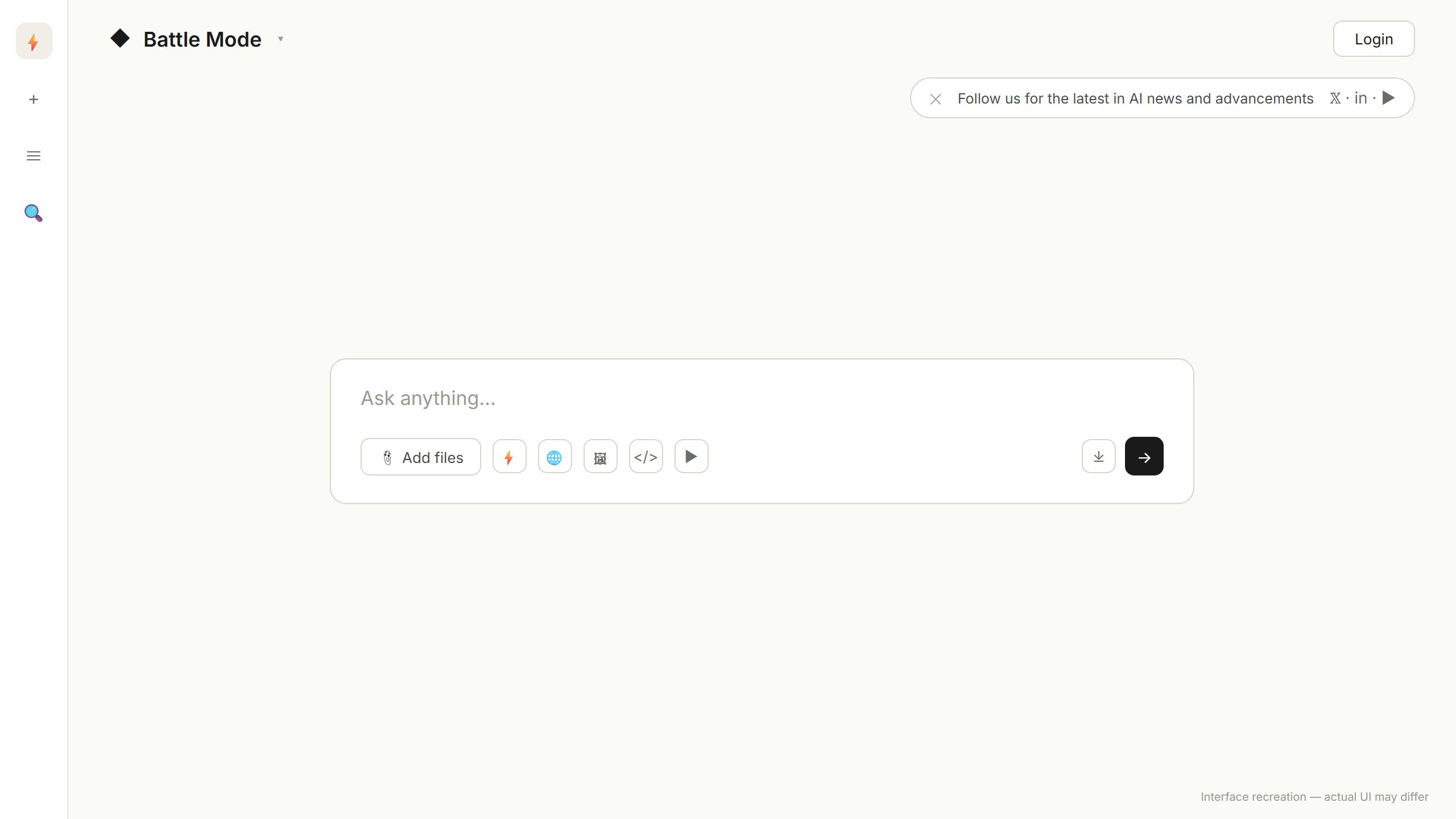
먼저 정직하게 말씀드리면 LM아레나는 한국어 인터페이스를 지원하지 않습니다. 메뉴·버튼이 모두 영어죠. 그런데 사용은 의외로 단순합니다. 메뉴 5개 정도만 알면 가입 없이 30초 안에 첫 배틀을 던질 수 있습니다.
5단계로 정리하면 이렇습니다.
- arena.ai 접속 — 가입·로그인 절대 안 해도 됩니다. 우상단
Login버튼은 무시하세요. - Battle Mode 기본값 확인 — 좌측 사이드바 첫 번째 메뉴가 이미
Battle Mode로 켜져 있습니다. 손 댈 필요 없음. Ask anything…박스에 한국어로 질문 — 한국어로 입력해도 정상 작동합니다. 답변 자체는 모델에 따라 한국어 또는 영어로 나옵니다.- 두 답변 비교 후 4개 버튼 중 1개 클릭 —
A is better(왼쪽이 좋음),B is better(오른쪽이 좋음),Tie(무승부),Both bad(둘 다 별로) 중 직관적으로 고르세요. - 투표 직후 모델 정체 공개 — “아 이게 GPT-5.5였구나”, “이건 Claude Opus 4.7이네” 하고 깨닫는 순간이 진짜 가치입니다.
첫 질문은 부담 없이 던져 보세요. 예를 들어 “Python에서 API 응답을 처리하는 가장 효율적인 방법은?”이라고 물으면, 왼쪽에는 하나의 AI 모델, 오른쪽에는 또 다른 모델이 각각 답변을 제시합니다. 하지만 어느 모델이 어느 답변을 한 건지는 보이지 않습니다. 이것이 “블라인드” 비교의 핵심입니다. 브랜드에 현혹되지 않고 답변의 질만으로 판단하도록 설계된 것이죠.

답변을 읽고 어느 쪽이 더 나은지 결정하면 투표가 완료됩니다. 투표 후 양쪽 모델의 정체가 공개됩니다. “아, 이게 Claude 4.7이구나” “이건 GPT-5.5네”라고 깨닫는 순간, 강한 임팩트를 받습니다. 차이를 직접 체감하게 되는 거죠.
카테고리별 아레나 — 내 업무에 맞는 분야 선택
2026년 현재 아레나는 더 이상 텍스트 답변만 비교하는 플랫폼이 아닙니다. 초기에는 “Chatbot Arena”라는 이름으로 순수 텍스트 질답만 평가했지만, 지난 6개월 동안 플랫폼이 급속도로 확장되었습니다. 멀티모달·이미지 생성·코딩 등 다양한 영역을 평가한다는 의미를 담아 2026년 1월에 “LMArena”에서 “Arena” 로 명칭을 변경했습니다.
주요 카테고리는 다음과 같습니다.
- Text Arena — 일반 텍스트 질의응답 (글쓰기, 분석, 창의적 콘텐츠). 현재 1위는 Claude Opus 4.7 Thinking (ELO 1503). 2위 Claude Opus 4.6 Thinking (ELO 1502)을 거의 따라잡으며 1위를 차지했습니다.
- Code Arena — 프로그래밍 과제 (버그 수정, 알고리즘 작성, 리팩토링). 가장 큰 성능 차이가 나타나는 영역으로, 역시 Claude Opus 4.7 Thinking (ELO 1571)이 1위, 일반 Claude Opus 4.7 (ELO 1565)이 2위입니다. 생각하는 과정이 코드 작성에서 얼마나 중요한지 보여주는 결과입니다.
- Vision Arena — 이미지 분석 및 설명 (사진 해석, 다이어그램 읽기, OCR). Claude Opus 4.7 Thinking (ELO 1303)과 Claude Opus 4.6 Thinking (ELO 1303)이 동점 1위, Claude Opus 4.7이 3위 (1302).
- Search Arena — RAG(검색 기반 답변) 평가. Claude Opus 4.6 Search (ELO 1253)가 1위, GPT-5.5 Search (ELO 1237)가 2위입니다.

그 외 Document Arena, Text-to-Image Arena, WebDev Arena 등도 최근 추가되었습니다. 자신의 주요 업무에 맞는 카테고리를 선택해 배틀하면, 그 분야에서 어느 모델이 가장 실용적인지 판단할 수 있습니다.
실전 팁 — 차이를 확실히 보는 방법
아레나는 단순히 모델을 구경하는 플랫폼이 아닙니다. 어떤 질문을 던지느냐에 따라 모델 간 차이가 극적으로 벌어집니다.
추론이 필요한 질문을 던져보세요. “이 수학 문제를 풀어줄래?”나 “이 코드 로직의 문제점은?”처럼 단순 조회가 아니라 생각하는 과정이 필요한 질문을 하면, Claude Opus의 Thinking 시리즈가 얼마나 강한지 즉시 느껴집니다. 반면 일반적인 정보 검색(“파이썬이 뭐야?”)에서는 차이가 작을 수 있습니다.
한국어 질문도 던져보세요. LM아레나는 영문 플랫폼이지만, 한국어로 물어도 잘 작동합니다. 특히 한국 독자 입장에서 중요한 건 “한국어 뉘앙스를 정확히 캐치하는가”인데, 이 부분에서 Claude 모델들이 일관되게 높은 평가를 받는 모습을 볼 수 있습니다. 강의에서 학생들에게 구글이 제미나이에 노트북LM을 통째로 넣었습니다 글에서 다룬 제미나이와 직접 비교하는 시연을 해보면 반응이 확연히 다릅니다.
진짜 매력 — 결제 없이 신규 AI를 무료로 시승
여기서 LM아레나의 가장 큰 매력을 솔직히 말씀드리겠습니다. 신규 모델을 결제 없이 다 써볼 수 있다는 점입니다. 비교·투표 기능은 사실 부수적이고, 일반인 입장에서는 이게 진짜 사용 이유입니다.
ChatGPT Plus 월 3만 원 안팎, Claude Pro 월 3만 원 안팎, Google AI Ultra 월 3만 원 — 다 합치면 작은 돈이 아닙니다. 그런데 이 모든 유료 모델을 LM아레나에서 결제 없이 던져볼 수 있습니다. 새로 출시된 GPT-5.5, Claude Opus 4.7, 신규 Gemini 같은 최신 모델도 마찬가지입니다.
저는 새 AI 발표 뉴스를 보면 제일 먼저 LM아레나를 켭니다. 발표 회사 사이트에 가서 “사용해보기”를 눌러 가입하고 결제할 필요 없이, 여기서 같은 질문 두세 번 던져 보고 “이 AI는 정말 살 만할까”를 결정하는 거죠. 구독 고민하던 독자분들도 가장 빠르게 답을 얻을 수 있는 길이 바로 여기입니다.
특히 이미지 생성 분야가 압권입니다. Text-to-Image Arena에 들어가면 OpenAI의 GPT 이미지 2.0, Google Imagen, Midjourney 같은 한 장 생성에 몇백 원~몇천 원 들어가는 유료 이미지 모델들을 결제 한 번 안 하고 던져볼 수 있습니다. 광고용 이미지 한 장 만들려는데 어느 모델이 한국어 텍스트를 정확히 그릴까 결정해야 한다면, 여기서 다섯 번 시도해 보고 결정하면 됩니다.
음악 모델도 마찬가지입니다. Music Arena에 들어가면 Suno, Udio 같은 유료 음악 생성 AI를 무료로 던져볼 수 있습니다. 강의용 배경음악이나 짧은 시그널 사운드가 필요할 때 이 한 곳에서 비교하고 끝낼 수 있다는 거죠.
그러니까 정리하면 이렇습니다. LM아레나는 표면적으로는 “AI 비교 사이트”지만, 실제로는 결제 없이 신규 유료 AI 다 시승해 보는 사이트입니다. 초보자가 지갑 열기 전에 들러야 하는 첫 정거장이라고 보면 됩니다.
다른 비교 도구와는 뭐가 다를까?
AI를 비교하는 방법은 여러 가지입니다. 학술 시험 점수(연구자들이 만든 표준 시험지에 모델이 몇 점 받았나)를 보거나, 각 회사 공식 문서를 읽거나, 직접 ChatGPT와 Claude를 따로따로 켜서 같은 질문을 던져 보는 방식들이죠. 그런데 LM아레나는 이들과 다릅니다.
가장 핵심 차이는 블라인드 방식입니다. 일반 벤치마크는 어느 모델이 답했는지 드러나고, 각 사이트 채팅은 브랜드 로고가 보여줍니다. 그러면 무의식적으로 선호가 섞입니다. “어? 이건 OpenAI인데 생각보다 좋네” 같은 심리가 작동하는 거죠. LM아레나는 이런 편향을 제거합니다. 당신은 왼쪽 답과 오른쪽 답만 보고, 어느 AI인지 나중에 알게 되는 방식입니다.
또 500만 명의 일반 사용자가 매월 투표하는 것도 차별점입니다. 연구자들의 학술적 기준이 아니라, 실제로 AI를 쓰는 사람들의 만족도를 수집합니다. 강의실에서 학생에게 “어느 AI가 더 도움 됐어?”라고 물어보는 것과 가깝습니다.
그런데 논란도 있습니다
완벽한 도구는 없습니다. LM아레나도 마찬가지입니다. 2025년에 한 연구팀이 지적한 바에 따르면, 대형 AI 회사들이 공개 전에 자기 모델을 몇십 개씩 비공개로 먼저 테스트해 보고 그중 가장 점수 잘 나온 버전만 공개한다고 합니다. Meta는 27개, Google은 10개 모델을 이렇게 사전 점수 측정만 해 본 것으로 알려졌습니다. 모두에게 공평한 경기는 아니라는 뜻입니다.
또 사용자의 심리 편향도 있습니다. 길게 답변하는 모델이 더 정확하다고 착각하게 만들고, 불릿 포인트와 마크다운 서식이 많은 답변이 신뢰스러워 보이게 합니다. 그래서 일부 모델은 불필요하게 길게 쓰고 과하게 꾸미는 법을 배우게 됩니다. 이건 실제 사용성과는 다릅니다.
그래서 절대적 기준으로 쓰면 안 됩니다. 한 달간 써 본 결론은, LM아레나는 좋은 참고 자료지만 마지막 판단 기준은 아니라는 것입니다. 여기 상위 모델도 실제 당신의 작업에 안 맞을 수 있습니다. 표준 시험 점수도 보고, 무엇보다 직접 던져 본 본인 경험이 가장 중요합니다.
누가 써야 할까?
그럼 누구에게 유용할까요?
비프로그래머 입니다. 코딩을 모르는 사람이 “어느 AI가 내 업무에 더 잘 맞을까?”를 판단할 때, 긴 문서 읽기보다 LM아레나에서 2~3번 배틀해보는 게 훨씬 빠릅니다. 기술 용어 몰라도 “아, 이 답이 더 자연스럽네” 정도 판단할 수 있으니까요.
AI 강사도 도움됩니다. 강의 중에 “그럼 어느 AI가 더 나을까요?”라는 학생 질문이 나올 때, 그 자리에서 라이브로 LM아레나를 띄워서 비교하면 학생 반응이 확 달라집니다. 추상적인 설명보다 눈으로 직접 보는 게 훨씬 설득력 있습니다. 실제로 강의 현장에서 바로 사용할 수 있는 도구를 찾는다면, 촬영 없이 강의 영상 만드는 법, Vrew 7단계 공식 글처럼 교육자를 위한 도구들이 있습니다.
기업 의사결정자도 마찬가지입니다. 수십 개 모델 중 팀이 쓸 AI를 고르려면, 임원진 보고에서 “이 모델이 실제로 이런 상황에서 이 정도로 좋습니다”라고 시각적으로 보여주는 게 도움됩니다. 딱딱한 벤치마크 수치보다 실제 답변 사례가 설득력 있으니까요.
이전에 다룬 무료가 너무 강해서 유료를 못 올렸습니다 — 릴리스AI 한 달 후기에서 다뤘던 것처럼, 구독 결정 앞두고 “이 AI를 정말 사야 할까?”라고 고민할 때 LM아레나는 명확한 답을 줍니다.
정리하면
LM아레나는 두 얼굴을 가진 사이트입니다. 회사 마케팅이 아니라 실제 사용자 투표로 순위가 매겨진다는 점에서 참신한 비교 도구이고, 동시에 결제 없이 신규 유료 AI를 다 시승해 볼 수 있는 무료 체험소이기도 합니다. 일반인 관점에서는 두 번째 얼굴이 진짜 매력입니다.
랭킹은 참고만 하시되, 거기 1위 모델보다 본인이 직접 던져 봤을 때 더 자연스러운 답을 한 모델이 본인에게 맞는 AI입니다. 구독 결정 앞두고 한 번이라도 LM아레나에 들러 보세요. 한 달치 결제 비용을 아낄 수도 있고, 아니면 진짜 살 만한 AI를 확신하고 결제하게 됩니다.
다음 사용기는 AI가 만드는 이미지를 다루겠습니다. GPT 이미지 2.0이라는 신규 모델인데, 일반 생성형 AI와는 다른 방식으로 만들어진다고 합니다. 그게 정말 다를까요?
참고 출처





